Tests Don't Have Special Permission To Repeat Themselves
Question
I find that having complex tests, with many private methods hiding information, results in high cognitive-load code, not so easy to read and understand later. I think, then, that DRY does not ever apply to tests: do you agree? Please let me know if so, and when you find it not useful, or worse, damaging.
Discussion
Generally speaking, I apply the same design principles to tests that I apply to production code. This means that I prefer to remove duplication from tests, even though I often become so excited making new tests pass that I copy and paste too much up front, trusting myself to remove that duplication later. This means that I apply DRY to my tests, although I sometimes apply it a little less strictly while writing the tests, giving the tests more time to stabilize, then relentlessly removing duplication before considering my work complete. Even if I don't remove the duplication right away, I look for and remain skeptical of all duplication in my tests.
The Trouble with "Test Helpers"
Removing duplication in tests often leads to extracting so-called "test helpers". These are functions that reside in the test modules that implement the classic Composed Method pattern: each describes a step that several tests have in common. Common test helpers include setting up test data, customized assertions, and configuring expensive external resources (databases, file systems, network services) to point to a consistent resource used just for testing. Extracting all these functions should help document the tests and hide details, but quite often, they appear to cause confusion over time, until nobody feels quite sure what's happening, when, how, nor why. Frustrated, they blame the test helpers.
Well... yes and no.
Removing duplication means extracting duplication into new elements of the design: functions, objects, modules, namespaces—it depends on the language you're using. Creating new elements of the design means that you need to organize these new elements. It's not enough just to throw a bunch of new functions into a junk drawer and hope for the best. Sadly, by framing these functions as "test helpers", somehow programmers feel like they don't have permission to organize these new structural elements beyond putting them in a test package somewhere. Please remember that test code is still just code and the same principles of organizing code apply. Removing duplication without introducing useful abstraction misses the more important half of the primary benefits of this principle.
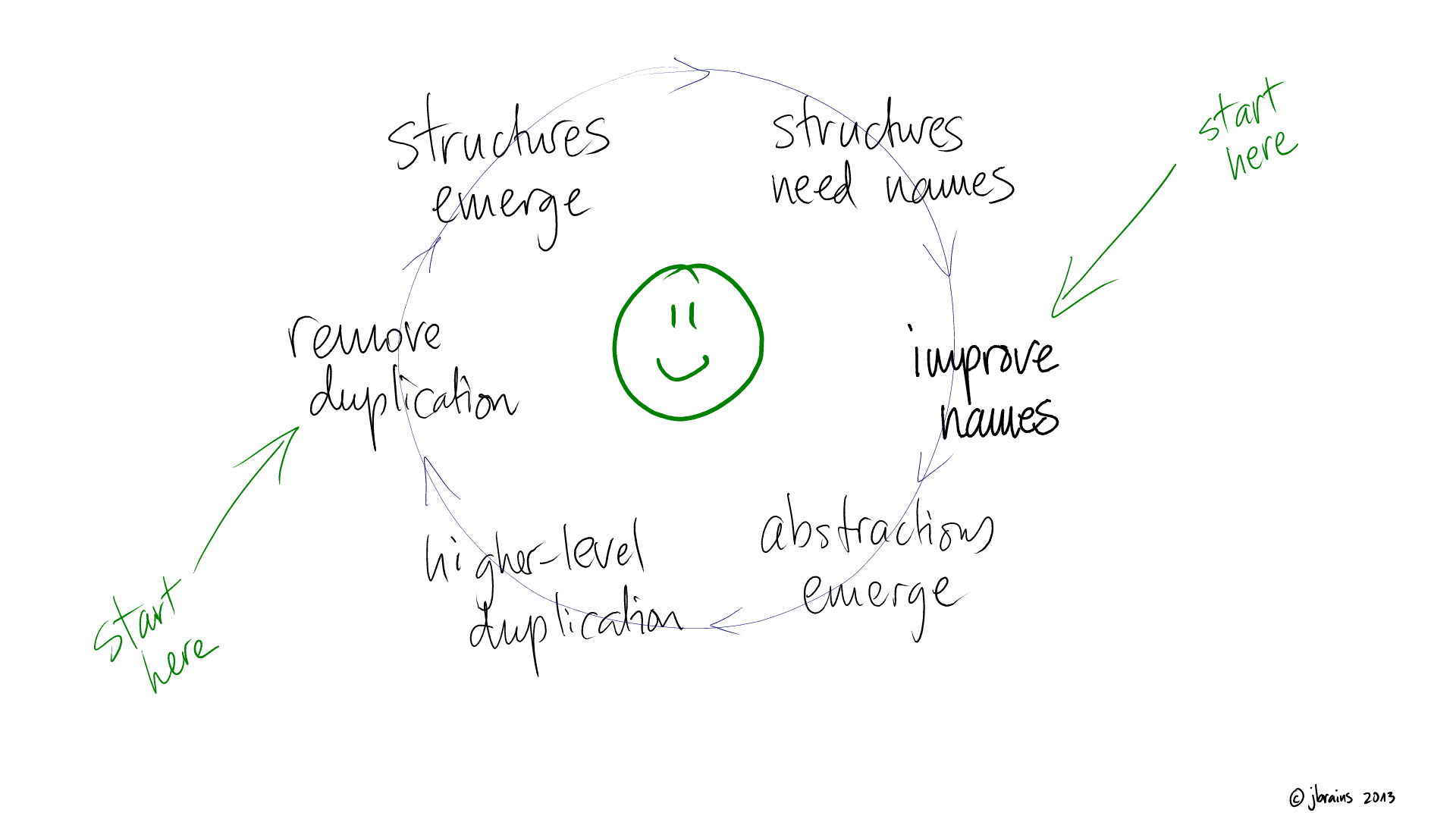
We remove duplication first "merely" to avoid divergent behavior in similar parts of the system, such as happens by the copy-paste-modify loop. More significantly, over time removing duplication helps us identify higher-level patterns in the code that emerge as potential abstractions which will help us reason more easily about a part of the system without having to understand all the details of the entire system at once!
If removing duplication from your code makes it more complicated instead of less complicated, then you're ignoring the abstractions trying desperately to emerge from the code. You can apply this idea just as well to test code as to production code!
Test Helpers Are Often Hidden Production Code!
This is one of those effects that I have observed and trust, but still haven't learned to explain adequately, so I'm forced to ask you to trust me when I say that most code that starts out life as a "test helper" eventually becomes useful production code. The simplest place to observe this effect is in so-called "test data helpers": functions that help us generate test data, often by hiding extraneous attributes that don't interest us in most of our tests.1 I often find that I want to move some of those creation methods into production code as new Named Constructors on the objects they're creating. I think I understand why this happens.
- Every test is a tiny, independent application that runs some portion of the system.
- A group of tests that want to create, for example, a Customer object by specifying (and ignoring) the same set of attributes acts like a group of applications that want to reuse some common code, rather than reimplement their own copy of it. No one test "owns" the code.
- Tests are examples of how production clients can and should use a given part or layer of the production code. As tests check smaller, more focused parts of the production code, tests of layer n and the production code in layer n+1 (that uses layer n) develop more similar goals and needs.
- Almost by magic or coincidence, this means that if today a group of tests has a specific pattern of using the production code, then eventually some other production client will want to use that same production code in a similar fashion. What is useful to the tests today becomes useful to some production code tomorrow.
I admit that this isn't as clear as I'd like it to be, but as I have previously admitted, the idea remains somewhat nebulous in my mind, even though I've seen the pattern over and over. Eventually, I'll be able better to explain how the effect happens.
All this means, however, that eventually someone on the project will ask, "Do we have anything that does X?" and, with luck, someone else will answer, "Yes, but only somewhere in the tests." Great! Now you can move that so-called "test helper" into the production design so that both the (old) tests and the (new) production code can both depend on the same newly-extracted behavior. It sounds good to me!
Extracting Without Organizing is the Problem
Applying DRY or removing duplication causes problems if we don't take steps to organize the new structural elements that we extract. This applies equally to production code and tests. Complicated, difficult-to-follow tests are just a special case of the mistake of indirection without abstraction. We organize new structural elements by looking for patterns and grouping similar things together and pushing different things farther apart. This way, abstractions emerge. This is part of the Simple Design Dynamo.
{kind=link}
A Good Reason For Smaller Tests
Have you noticed that small tests—meaning tests that check a smaller, more focused part of the system—don't suffer from becoming complicated in quite the same way that larger tests do? Integrated tests really are a scam.
Release Your Obsession With Details
The procedural programmer's mind is obsessed with details. This isn't necessarily a bad thing, but it's in direct conflict with modularity, a property of design that I'm guessing most of you value. You can't have both. If you think you want to know all the detailed steps of every test, then you won't ever be able to escape those details, and you won't ever be able to comfortably reason about the system as a whole. The resulting systems are a patchwork of contradictory bits and pieces that, over time, become increasingly and alarmingly difficult to change. Modular designs just don't have that problem: when something significant changes, we detach a layer, rearrange the pieces, and reattach it in the one place it connects to the system. That's the power of modularity, but to get it, you have to release your obsession with details.
The Magic of Abstraction
I just thought of something... removing duplication leads to new structural elements, which we need to organize into new abstractions, and if the abstractions are truly abstract, then they will depend less on their context and it will be easier to use them in other parts of the design... including production code. This must be how the magic happens: abstraction makes reuse more likely. It really can be just that simple.
Reactions
Just today @tomliversidge & I extracted a bunch of TestHelpers & then realised it was really aShopper#clarity https://t.co/myk0HsHzbA
— Paul D'Ambra (@pauldambra) June 7, 2016
References
J. B. Rainsberger, "Injecting Dependencies, Partially Applying Functions, and It Really Doesn't Matter". A description of tests as tiny, independent applications, and how framing the design this way gives us useful flexibility in how test and production code designs evolve.
J. B. Rainsberger, "Beyond Mock Objects". Indirection without abstraction also fools programmers into believing that they hate mock objects and, by extension, pluggability and, you know, modularity. Silly programmers.
J. B. Rainsberger, "Putting An Age-Old Battle To Rest". How we get from Kent Beck's definition of simple design to the exact positive feedback loop that is the "magic machine" of evolutionary design (and test-driven development).
J. B. Rainsberger, "Modularity. Details. Pick One." Modularity and obsession with details exclude one another. If you want one, then you can’t have the other, so pick one.
- Think of a Customer object. Tests aimed directly at Customer behavior might care about all the Customer details, but the tests aimed at other parts of the system might only care about the Customer's ID and name.↩